Knowing whose turn it is to speak remains one of the hardest problems in voice AI. You’ve probably already used our transformer-based End-of-Turn detection that tells the agent when the user is truly done speaking.
But what about the other direction? When the agent is talking and the user wants to jump in?
The naive solution of stopping the moment the user makes any sound sounds simple on paper. In reality it destroys the conversation. Most voice agents today rely on simple Voice Activity Detection (VAD) when speech is detected during the agent’s turn. But VAD alone is not sufficient, because many sounds can trigger it: brief backchannels (“mm-hmm”, “yeah”), user noises like sighs or coughs, or background sounds like typing, music or chatter. Treat every one of those as a full interruption and your agent becomes jittery and robotic.
We’ve been focused on solving this properly for a long time. Today we’re excited to announce Adaptive Interruption Handling is generally available in LiveKit Agents.
How Adaptive Interruption Handling works#
We trained a brand-new audio-based interruption detection model specifically for this problem.
When user speech is detected during the agent’s turn, the model analyzes the user’s audio stream within the first few hundred milliseconds of detected speech. It looks for distinctive acoustic characteristics of true interruptions, including:
- Overall waveform shape
- Strength and sharpness of speech onset
- Duration of the signal
- Prosodic features such as pitch and rhythm
This allows it to quickly determine whether the user is beginning a new utterance or just making incidental sounds.
To learn these patterns, the model was trained on examples of real interruptions, backchannels, and other sounds extracted from natural one-on-one conversations. It learned to discriminate between genuine attempts to interrupt and incidental speech or noise that would normally trigger a simple VAD.
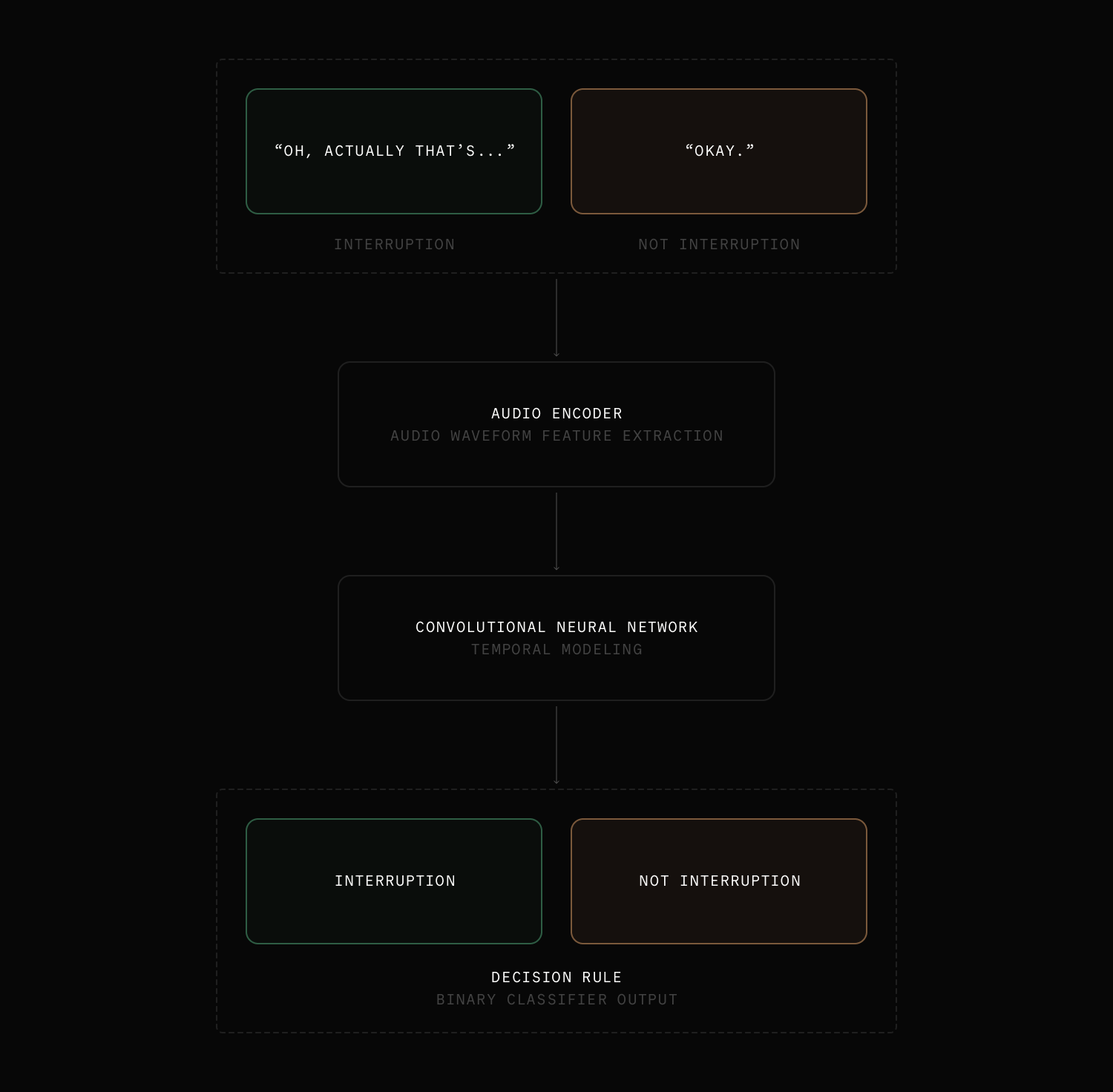
Architecturally, the system combines an audio encoder with a convolutional neural network (CNN) to extract and analyze acoustic patterns in the waveform. This design enables the model to identify the signatures of true interruptions while ignoring non-interruptive sounds, resulting in more natural and responsive conversations with the agent.
The data challenge#
In order to teach the model how to behave more human-like, we needed to gather a diverse set of conversations that capture natural back-channeling and barge-ins. This kind of data is very sparse in human-agent conversations, because most voice agents today simply aren’t able to handle it correctly.
Instead, we turned to human-to-human conversations. Our team went on a full data-gathering mission and collected hundreds of hours of real human speech across many different topics and language.
The raw audio then went through a data enrichment pipeline, mixing in a variety of noises to simulate the real-world diversity of inputs we expect to see.
One particularly exciting outcome is that the model is multilingual and generalizes effectively to languages it has never seen before. Rather than simply memorizing patterns from the training data, it has learned the underlying conversational dynamics and can infer correctly in new scenarios.
Benchmarks#
We evaluated the model on a held-out dataset and observed strong results in production:
- 86% precision and 100% recall (at 500 ms overlap speech)
- Rejects 51% of VAD-based barge-ins (false positives avoided)
- Detects true barge-ins faster than VAD in 64% of cases
- Completes inference in 30 ms or less
- Median audio duration needed to trigger interruption: 216 ms
- Consistent strong performance across noisy environments and multiple languages
Using Adaptive Interruption Handling#
The model is enabled by default in Python Agents v1.5.0+ and TypeScript Agents v1.2.0+. Every agent deployed to LiveKit Cloud gets it automatically with no extra models to deploy or manage.
To fall back to classic VAD-based interruption detection, use the new turn_handling config:
Python
1session = AgentSession(2...3turn_handling=TurnHandlingOptions(4interruption={5"mode": "vad",6},7),8)
TypeScript
1const session = new AgentSession({2interruption: {3mode: "vad",4},5})
When interruption.mode is not specified, it defaults to "adaptive" on LiveKit Cloud or in dev mode.
This model is deployed directly in LiveKit Cloud data centers for optimal inference latency. We’ve been building a family of models that significantly improve conversational flow. They’re trained on proprietary data, tend to be larger, and are optimized for GPU inference, making them impractical to bundle into agent containers.
Adaptive Interruption Handling is included at no extra cost for all agents deployed to LiveKit Cloud.
For local development and testing, every plan includes 40,000 free inference requests per month.
Try it today#
Adaptive Interruption Handling is the missing piece that makes voice agents feel truly conversational instead of polite but robotic.
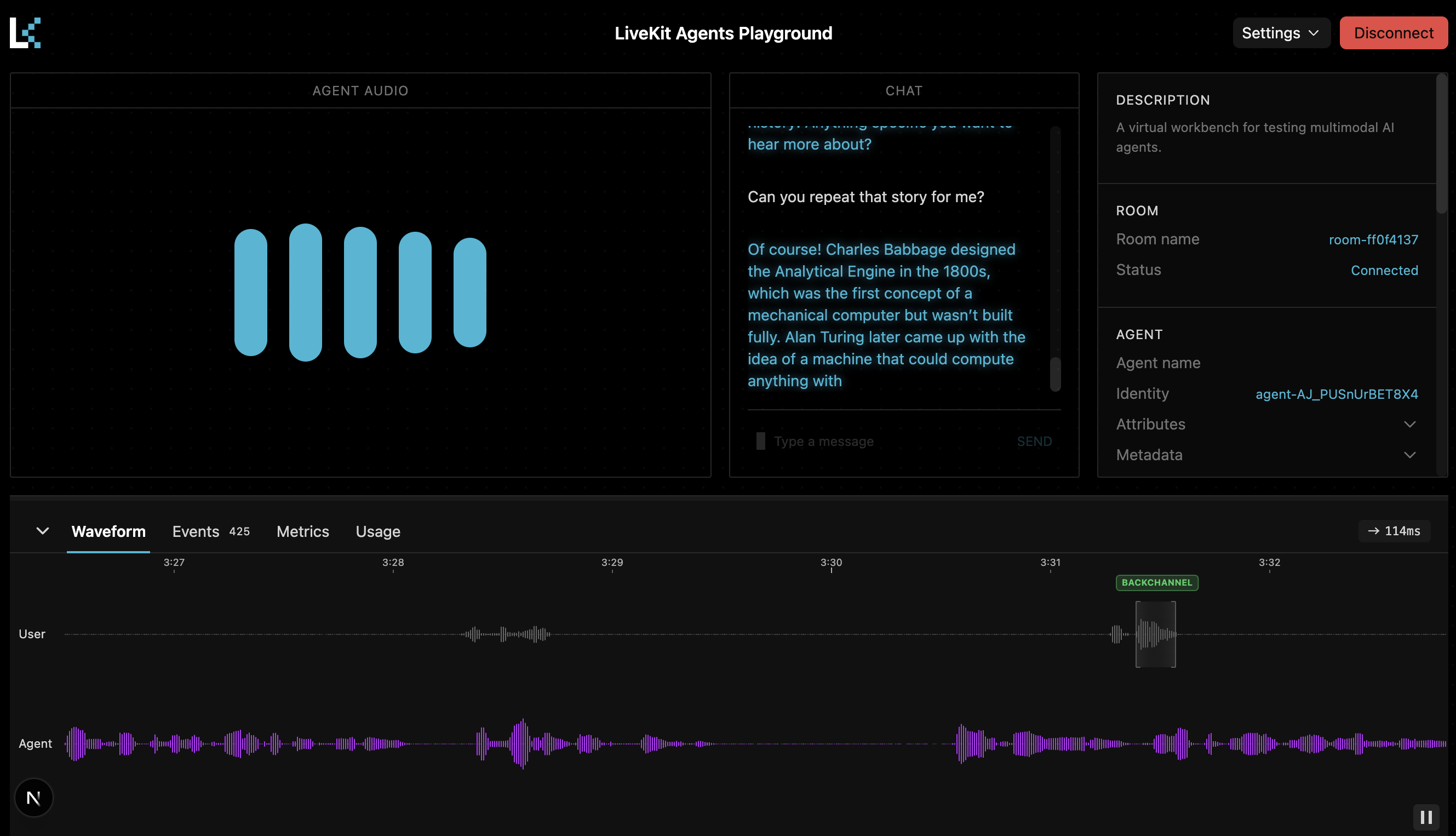
The fastest way to try it is in the Agent Console. Run an agent on your machine, speak over it, or backchannel and see the difference immediately.
We’ve also added a brand-new debugging panel with clear visualizations that show exactly when the model detects a barge-in versus a back-channel. It makes debugging and tuning extremely straightforward.
Give it a try! We’d love to hear what you build and any feedback you have.