Every voice agent has to answer the same question, over and over, on every pause: is the user done talking? Answer too early and the agent talks over people. Answer too late and the conversation fills with dead air. End-of-turn detection is the difference between a voice agent that feels like a conversation and one that feels like a walkie-talkie, and it has been one of the hardest open problems in voice AI since the first agents shipped.
Today we're releasing two models that listen to the user's speech directly instead of waiting on a transcript, fusing semantic and acoustic understanding into a single end-of-turn prediction. LiveKit Turn Detector v1 posts the strongest results of any model we evaluated, across English and 13 other languages. It runs on optimized inference in LiveKit Cloud, at no charge for agents running there, and is now the default. v1-mini is an open-weight model with the same architecture, optimized for fast CPU inference.
Our goal with v1 was to make turn detection so good that you never have to think about it. With this release, we consider end-of-turn detection a solved problem for agents built on LiveKit.
The long road to this release#
We've been working on this problem for a while. In 2024 we shipped an open-source transformer model for turn detection that used the semantic content of the transcript to predict whether a user had finished a thought. Later versions cut unwanted interruptions by 39% and extended coverage to more languages. Each generation got better at understanding what users were saying.
But text-based models, however good, share a ceiling. To break through it, we had to stop reading and start listening.
Why text alone falls short#
Text-based end-of-turn models are highly effective at capturing user intent and semantic meaning. But relying on text alone imposes three structural limits.
First, the model is only as good as the transcript it's fed: errors, latency, or inconsistencies in speech-to-text directly degrade predictions. Second, transcription itself adds delay, since inference can't begin until the final transcript arrives, and that latency lands directly on the agent's response time. Third, and most fundamentally, reducing speech to text throws away the timing and acoustic signals that tell you when a speaker has actually finished.
Consider two cases where a user pauses after "pizza":
Agent: What would you like to order?
User: I would like to order one large pizza…
Agent: What would you like to order?
User: I would like to order one large pizza… and a garlic bread
At the moment of the pause, the transcript is identical in both cases. No amount of semantic modeling can distinguish them, because the distinction isn't in the words; it's in how they're delivered. Humans resolve this effortlessly using paralinguistic cues: intonation, pitch, rhythm. An upward inflection signals an unfinished thought; a drop in pitch often signals completion. When speech is reduced to text, those signals are gone.
Listening instead of reading#
LiveKit Turn Detector v1 keeps the LLM backbone our previous models used for semantic reasoning, and adds audio encoders that process the user's speech directly. The model captures both what is being said and how it's being said, with no transcription step in between.
The semantic branch uses an audio encoder, a learned adapter, and a fine-tuned language model. The adapter projects the user's audio into the embedding space of the LLM, so the model gets the same kind of semantic signal a text-based version would, without ever going through a transcript. The acoustic branch runs a separate encoder into a recurrent layer that captures timing and prosody. A fusion module combines both encodings into a single end-of-turn prediction.
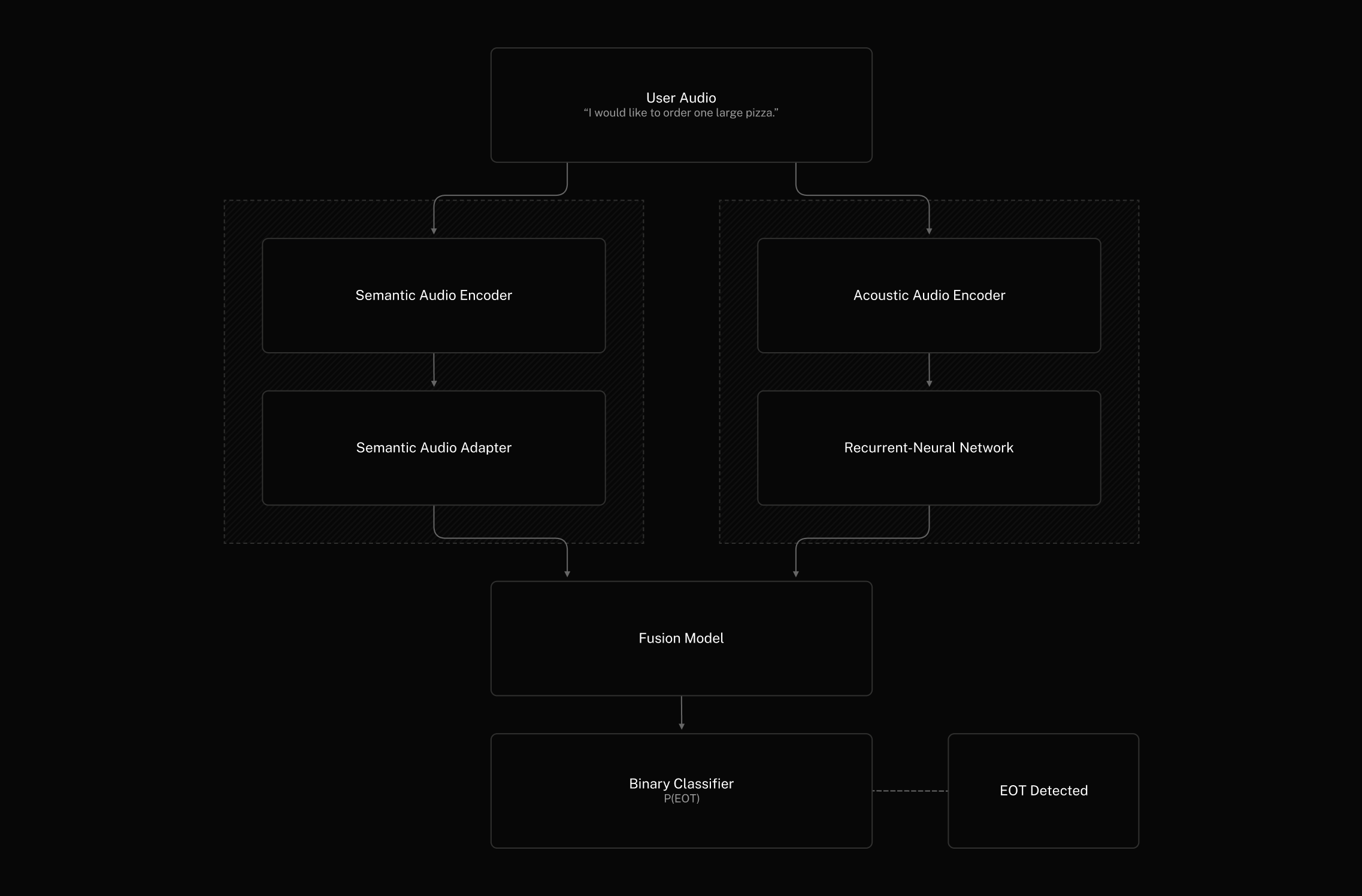
This design has two practical consequences. The latency cost of waiting for a transcript is gone: inference proceeds directly from the audio stream. And because the acoustic branch carries strong information about the current user turn, the model no longer needs prior turns of chat context the way text-only versions did. It looks at the current user turn only, which keeps the context window short and inference fast.
An open benchmark for end-of-turn detection#
A claim like "state of the art" raises an immediate question: state of the art on what? There are no established public benchmarks for end-of-turn detection. Every provider evaluates on private data, with methodologies that rarely match how models behave in production. That makes results impossible to compare and impossible to reproduce.
So alongside v1, we're releasing eot-bench, an open benchmark suite for end-of-turn detection, together with open datasets of real user turns spanning English and 13 other languages. It's the foundation of every result in this post, and we hope it becomes the standard way end-of-turn models are measured. If you're building one, we'd love to see your numbers.
The suite evaluates turn detection the way production voice agents experience it: every pause inside a user turn is a decision point. The system should wait through mid-turn pauses, then respond quickly at the final one. It compares each model under full endpointing policies, not just raw model scores, sweeping the policy settings that control how confidently and how quickly the assistant takes the floor, then measuring the tradeoff between response latency and false cutoffs.
Benchmark results#
Explore the latency/false-cutoff tradeoff directly below. Set a latency budget or a false-cutoff budget, by dragging the line on the curve or with the slider, and the ranking and per-language heatmap update to show where each model lands at that operating point.
LiveKit v1 has the strongest overall frontier in our evaluation. At a 300 ms latency budget, it reaches a 9.9% false-cutoff rate, compared with 12.9% for Deepgram Flux and 27.7% for ultraVAD. At 600 ms, it reaches 4.5%, ahead of Soniox at 5.5% and Deepgram Flux at 9.9%. The same pattern holds when we fix the interruption budget instead: at a 5% false-cutoff target it reaches 543 ms mean latency, and at 10% it reaches 295 ms, the best result among the evaluated models in both settings.
State of the art in 14 languages#
We ran the same suite across 14 languages. Switch the per-language heatmap in the explorer above between latency and cutoff budgets: LiveKit v1 is the strongest overall multilingual model, winning most language-by-metric comparisons across both latency and false-cutoff operating points.
Solved by default in LiveKit Agents#
Some speech-to-text providers have started building end-of-turn detection directly into their models. We understand the appeal, but in practice these built-in detectors tend to come with incomplete language coverage and performance that varies unpredictably from one provider to the next. When turn detection lives inside your STT vendor, the conversational feel of your agent is coupled to that vendor: switching providers changes how your agent handles pauses and interruptions, and your language coverage is capped at whatever the vendor supports.
We believe this is a problem the agent framework is best equipped to solve. Turn detection in LiveKit Agents works the same way no matter which STT, LLM, or TTS you choose, with no dependence on vendor-specific behavior from model providers. We solve the end-of-turn problem identically regardless of the nuances of individual models, so you keep maximal flexibility in your model stack while your agent's turn-taking stays consistent. One model, one behavior, across every provider and 14 languages.
The full v1 model is available today at no cost for agents hosted on LiveKit Cloud. And for local development and testing, every plan includes 7,500 free inference requests per month via LiveKit Inference.
It's the default turn detector whenever your agent runs with LiveKit Cloud, both deployed to Cloud and in local development with LiveKit Cloud credentials present, so there's nothing to set up unless you choose otherwise. To select it explicitly:
1from livekit.agents.inference import TurnDetector23session = AgentSession(4turn_detection=TurnDetector(),5# ...6)
1import { inference, voice } from '@livekit/agents';23const session = new voice.AgentSession({4turnDetection: new inference.TurnDetector(),5// ...6});
v1-mini#
v1-mini shares the same core architecture as v1. We quantized the weights and pruned the LLM backbone, which together shrink the model and drop inference latency significantly while preserving most of the accuracy, making it well suited to running on CPU.
The v1-mini model is bundled in our Agents SDKs (version 1.6.1 with livekit-agents in Python and version 1.4.7 in TypeScript), with the code under Apache-2.0 and the model files under the same LiveKit Model License as previous versions.
Getting started#
You can use the v1 model now:
- Turn detection in LiveKit Agents (docs)
- eot-bench benchmark suite on GitHub
- Evaluation datasets on Hugging Face
- Voice AI Quickstart
Questions, benchmarks, or pull requests? Join us in the LiveKit community.